进化强化学习有望进一步推进机器学习
进化强化学习是机器学习中令人兴奋的前沿,它结合了两种不同方法的优势:强化学习和进化计算。在进化强化学习中,智能代理通过积极探索不同的方法并获得成功表现的奖励来学习最佳策略。
这种创新范式将强化学习的试错学习与进化算法模仿自然选择的能力相结合,从而产生了一种强大的人工智能开发方法,有望在各个领域取得突破。
IntelligentComputing上发表了进化强化学习的综述文章。它阐明了进化计算与强化学习相结合的最新进展,并全面介绍了最先进的方法。
强化学习是机器学习的一个子领域,侧重于开发学习根据环境反馈做出决策的算法。成功强化学习的显着例子包括AlphaGo和最近踢足球的GoogleDeepMind机器人。
然而,强化学习仍然面临一些挑战,包括探索和开发权衡、奖励设计、泛化和信用分配。
进化计算模拟自然进化过程来解决问题,为强化学习问题提供了一种潜在的解决方案。通过结合这两种方法,研究人员创建了进化强化学习领域。
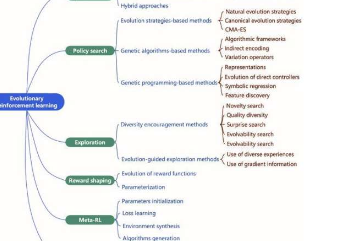
进化强化学习包括六个关键研究领域:
超参数优化:进化计算方法可用于超参数优化。也就是说,它们可以自动确定强化学习系统的最佳设置。由于涉及多种因素,例如算法的学习速度及其对未来奖励的倾向,手动发现最佳设置可能具有挑战性。此外,强化学习的性能在很大程度上取决于所采用的神经网络的架构,包括其层数和大小等因素。
策略搜索:策略搜索需要通过在神经网络的帮助下尝试不同的策略来找到完成任务的最佳方法。这些网络类似于强大的计算器,近似执行任务并利用深度学习的进步。由于存在多种任务执行可能性,搜索过程就像在一个巨大的迷宫中导航。随机梯度下降是训练神经网络和在迷宫中导航的常用方法。进化计算提供了基于进化策略、遗传算法和遗传编程的替代“神经进化”方法。这些方法可以确定用于强化学习的神经网络的最佳权重和其他属性。
探索:强化学习代理通过与环境交互来改进。探索太少会导致错误的决策,而探索太多则代价高昂。因此,在代理人发现良好行为的探索与代理人对已发现的良好行为的利用之间存在权衡。代理人通过为其行为添加随机性来进行探索。高效探索面临挑战:大量可能的行动、稀有和延迟的奖励、不可预测的环境和复杂的多智能体场景。进化计算方法通过促进竞争、合作和并行化来应对这些挑战。他们鼓励通过多样性和引导进化进行探索。
奖励塑造:奖励在强化学习中很重要,但它们通常很少见,而且代理人很难从中学习。奖励塑造增加了额外的细粒度奖励,以帮助代理更好地学习。然而,这些奖励可能会以意想不到的方式改变代理人的行为,要弄清楚这些额外奖励应该是什么、如何平衡它们以及如何在多个代理人之间分配信用通常需要手头任务的具体知识。为了应对奖励设计的挑战,研究人员使用进化计算来调整单代理和多代理强化学习中的额外奖励及其设置。
元强化学习:元强化学习旨在开发一种通用的学习算法,该算法可以利用以前的知识适应不同的任务。这种方法解决了传统强化学习中需要大量样本从头开始学习每个任务的问题。然而,使用元强化学习可以解决的任务的数量和复杂性仍然有限,并且与之相关的计算成本很高。因此,利用进化计算的模型不可知和高度并行特性是释放元强化学习全部潜力的一个有前途的方向,使其能够在现实场景中学习、泛化并提高计算效率。
多目标强化学习:在一些现实世界的问题中,存在多个相互冲突的目标。多目标进化算法可以平衡这些目标,并在没有解决方案看起来比其他解决方案更好时提出折衷方案。多目标强化学习方法可以分为两种类型:将多个目标组合成一个以找到单个最佳解决方案的方法和找到一系列好的解决方案的方法。相反,一些单一目标问题可以有效地分解为多个目标,使问题解决更容易。
进化强化学习可以解决复杂的强化学习任务,即使是在具有罕见或误导性奖励的场景中也是如此。但是,它需要大量的计算资源,因此计算成本很高。人们越来越需要更有效的方法,包括改进编码、采样、搜索运算符、算法框架和评估。
虽然进化强化学习在解决具有挑战性的强化学习问题方面已经显示出可喜的成果,但仍有可能取得进一步的进展。通过提高其计算效率并探索新的基准、平台和应用程序,进化强化学习领域的研究人员可以使进化方法更加有效和有用地解决复杂的强化学习任务。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【别克gl8商务车怎么样】别克GL8自推出以来,凭借其出色的舒适性、空间表现和品牌口碑,成为国内高端商务用车...浏览全文>>
-
【别克gl8商务车油耗是多少】别克GL8作为一款经典的商务车型,凭借其宽敞的内部空间、舒适的乘坐体验和较高的...浏览全文>>
-
【别克gl8商务车油耗多少】别克GL8是一款非常受欢迎的中大型MPV,广泛用于商务接待、家庭出行以及出租车等场景...浏览全文>>
-
【别克gl8商务车价格多少】别克GL8作为一款经典的商务车型,凭借其舒适性、空间表现以及品牌口碑,深受企业用...浏览全文>>
-
【别克gl8商务车价格】作为一款在国内市场广受好评的中高端商务车型,别克GL8凭借其宽敞的内部空间、舒适的乘...浏览全文>>
-
【别克gl8商务车多少钱】别克GL8作为一款经典的商务车型,凭借其舒适性、空间表现和品牌口碑,在国内市场上一...浏览全文>>
-
【别克gl8商务车的参数是怎样的】作为一款在商务用车市场中备受青睐的车型,别克GL8凭借其宽敞的空间、舒适的...浏览全文>>
-
【别克gl8商务车参数】作为一款在市场上备受关注的中高端商务车型,别克GL8凭借其宽敞的空间、舒适的驾乘体验...浏览全文>>
-
【别克gl8商务车报价参数配置】别克GL8作为一款经典的商务车型,凭借其宽敞的内部空间、舒适的乘坐体验以及较...浏览全文>>
-
【别克excelle是哪款车】“别克Excelle”这一名称在汽车市场中并不常见,可能是对别克某款车型的误写或翻译差...浏览全文>>