新方法提高视觉转换器AI系统的效率
视觉转换器(ViT)是一种强大的人工智能(AI)技术,可以识别或分类图像中的对象——但是,在计算能力要求和决策透明度方面存在重大挑战。研究人员现在已经开发出一种新的方法来解决这两个挑战,同时还提高了ViT识别、分类和分割图像中对象的能力。
变形金刚是现有最强大的人工智能模型之一。例如,ChatGPT是一种使用transformer架构的AI,但用于训练它的输入是语言。ViT是基于变换器的AI,使用视觉输入进行训练。例如,ViT可用于检测和分类图像中的对象,例如识别图像中的所有汽车或所有行人。
然而,ViT面临两个挑战。
首先,变压器模型非常复杂。相对于插入AI的数据量,Transformer模型需要大量的计算能力并使用大量内存。这对ViT来说尤其成问题,因为图像包含太多数据。
其次,用户很难准确理解ViT是如何做出决定的。例如,您可能已经训练了ViT来识别图像中的狗。但目前尚不完全清楚ViT如何确定什么是狗,什么不是。根据应用程序的不同,了解ViT的决策过程(也称为模型可解释性)可能非常重要。
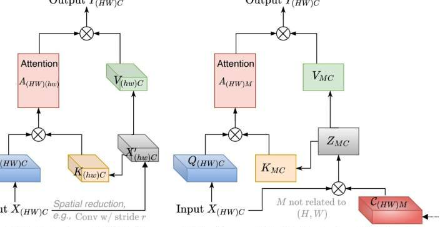
称为“补丁到集群注意力”(PaCa)的新ViT方法解决了这两个挑战。
“我们通过使用聚类技术解决了与计算和内存需求相关的挑战,这使得transformer架构能够更好地识别和关注图像中的对象,”该论文的通讯作者、该研究的副教授TianfuWu说。北卡罗来纳州立大学电气与计算机工程专业。
“聚类是人工智能根据它在图像数据中发现的相似性将图像的各个部分聚集在一起。这显着降低了对系统的计算需求。在聚类之前,ViT的计算需求是二次的。例如,如果系统崩溃将图像分解为100个更小的单元,它需要将所有100个单元相互比较——这将是10,000个复杂的函数。”
“通过聚类,我们能够使它成为一个线性过程,其中每个较小的单元只需要与预定数量的聚类进行比较。假设你告诉系统建立10个聚类;那将只有1,000个复杂的函数,”吴说。
“聚类还使我们能够解决模型的可解释性问题,因为我们可以首先了解它是如何创建聚类的。当将这些数据部分集中在一起时,它决定哪些特征是重要的?而且因为人工智能只创造了一小部分集群,我们可以很容易地查看它们。”
研究人员对PaCa进行了全面测试,并将其与称为SWin和PVT的两种最先进的ViT进行了比较。
“我们发现PaCa在各个方面都优于SWin和PVT,”Wu说。“PaCa更擅长对图像中的对象进行分类,更擅长识别图像中的对象,更擅长分割——本质上勾勒出图像中对象的边界。它也更高效,这意味着它能够比其他ViT。”
“我们的下一步是通过在更大的基础数据集上进行培训来扩大PaCa。”
论文“PaCa-ViT:在视觉转换器中学习补丁到集群的注意力”将在6月18日至22日在加拿大温哥华举行的IEEE/CVF计算机视觉和模式识别会议上发表。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【别克gl8商务车怎么样】别克GL8自推出以来,凭借其出色的舒适性、空间表现和品牌口碑,成为国内高端商务用车...浏览全文>>
-
【别克gl8商务车油耗是多少】别克GL8作为一款经典的商务车型,凭借其宽敞的内部空间、舒适的乘坐体验和较高的...浏览全文>>
-
【别克gl8商务车油耗多少】别克GL8是一款非常受欢迎的中大型MPV,广泛用于商务接待、家庭出行以及出租车等场景...浏览全文>>
-
【别克gl8商务车价格多少】别克GL8作为一款经典的商务车型,凭借其舒适性、空间表现以及品牌口碑,深受企业用...浏览全文>>
-
【别克gl8商务车价格】作为一款在国内市场广受好评的中高端商务车型,别克GL8凭借其宽敞的内部空间、舒适的乘...浏览全文>>
-
【别克gl8商务车多少钱】别克GL8作为一款经典的商务车型,凭借其舒适性、空间表现和品牌口碑,在国内市场上一...浏览全文>>
-
【别克gl8商务车的参数是怎样的】作为一款在商务用车市场中备受青睐的车型,别克GL8凭借其宽敞的空间、舒适的...浏览全文>>
-
【别克gl8商务车参数】作为一款在市场上备受关注的中高端商务车型,别克GL8凭借其宽敞的空间、舒适的驾乘体验...浏览全文>>
-
【别克gl8商务车报价参数配置】别克GL8作为一款经典的商务车型,凭借其宽敞的内部空间、舒适的乘坐体验以及较...浏览全文>>
-
【别克excelle是哪款车】“别克Excelle”这一名称在汽车市场中并不常见,可能是对别克某款车型的误写或翻译差...浏览全文>>